My previous post, Reproducible Notebooks in Jupyter Notes, ends with some PCA to cluster the data. Let’s take the next step, and actually try to predict bike traffic for each direction, holding back the most recent 2 weeks of data for testing.
This is overkill, but I think it demonstrates that deep learning can be used in smaller scale problems.
Analysis Plan
- load Seattle bike data
- create test training set with Oct 2017 data
- create training and validation (Sep 2017) datasets
- parse date features
Possibly cool explorations, time permitting
- use different sized train sets (last year, last 3 years, etc)
- add in seattle weather data
- change relative sizes of train/validate data. does it improve the model to have different months in the validation set?
Data
- First data is 10-03-2012
- Last data is 10-31-2017
- Test: 10-01-2017 -> 10-30-2017
- Validate: 09-01-2017 -> 09-30-2017
- Train: 10-03-2012 -> 08-31-2017
Validation and Training Sets
Our date range covers 1855 days: 10/12/2012 - 10/31/2017. Let’s re-examine the weekly traffic, from my previous article on reproducible practices for Jupyter notebooks.
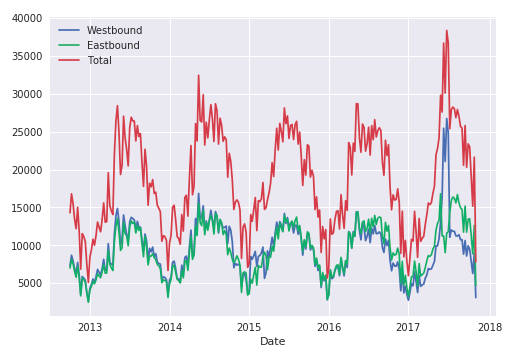
Everything looks good. We’re going to use September (09-01-2017) as our validation set. For time series data, FastAI professor/author Rachel Thomas recommends using a time period equal to the test set. One month is a convenient amount to predict, so we will also use 1 month (October) as validation, taking care to keep test data separate.
If your data is a time series, choosing a random subset of the data will be both too easy (you can look at the data both before and after the dates your are trying to predict) and not representative of most business use cases (where you are using historical data to build a model for use in the future). If your data includes the date and you are building a model to use in the future, you will want to choose a continuous section with the latest dates as your validation set (for instance, the last two weeks or last month of the available data).
-- Rachel Thomas, How (and why) to create a good validation set
Loading & wrangling
We’re going to process dates, using the fastai add_datepart() from fastai library.
add_datepart(df, fldname, drop=True)
add_datepart converts a column of df from a datetime64 to many columns containing the information from the date. This applies changes inplace.
That little piece of code will process the specified column, turning it into fields that reflect periodicity and date patterns (e.g., add an is_weekend column, day of week, etc.) Very cool!
A neat piece of code to save validation and test indexes:
val_idx = np.flatnonzero(
( df.index<=datetime.datetime( 2017, 9, 30 ) ) &
( df.index>=datetime.datetime( 2017, 9, 1 ) ) )
We do the same with the train/test indexes. This is a good time to explore your three datasets – make sure they represent the values you expect, are the size you expect, etc.
I’m going to explicitly copy the test data to a different python object and remove it from the dataframe we’ll use from here on out.
Separating as many features into categories allows us to create embedding matrices for them, which is a key tip for using deep learning w/ structured data. I’m going to define every column as categorical, except Date_ColElapsed, as that’s an integer with too many levels to be a categorical. We’ll use Total as the dependent variable, and need to exclude Westbound and Eastbound from the dataframe (otherwise the neural net might simply create a simpler adder).
This is a good point to save our cleaned/wrangled/feature extracted/datetime parsed object. feather is the preferred library.
End Part I.
Additional Reading
- Rachel Thomas covers how and why you should create good validation sets