A friend recently mentioned he was picking up Python, in an effort to dip his toes into the data science career path. He’s got a very strong theoretical grasp of programming, even if his preferred tools are JS and PHP.
I’ve been thinking about what he should learn, or be aware of. Now we’re all on the same page.
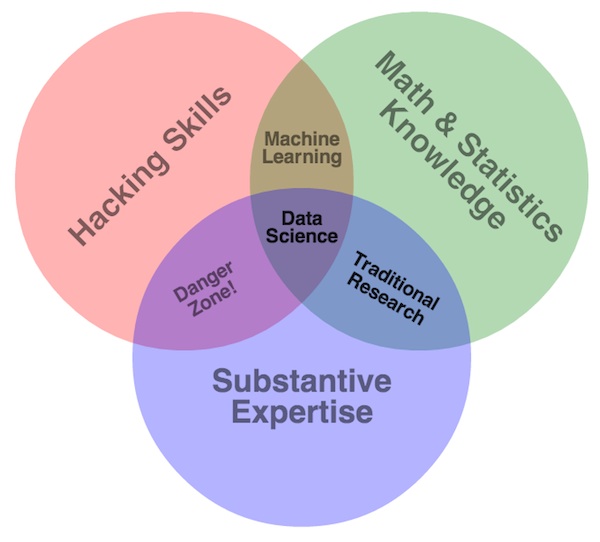
The common view of d.s. is the intersection of statistics, coding skills, and substantive expertise. I see it more as the intersection of coding skills, risk awareness (instead of Statistics), and Intellectual Curiosity (instead of domain knowledge).
Statistical knowledge is important, but you don’t need to be an expert. Be aware of the risks and tradeoffs of the techniques you use, be aware you will be biased towards results you want (very bad thing; the biggest ‘gotcha’ in the field, and ruiner of models). Most of the time, the statistical work is fairly minimal, but the data discipline / risk awareness is important.
Substantive Expertise is fraught with biases and peril. In “traditional” ML, you needed an expert to engineer the features you’d build into models – you need someone to tell you what’s significant in the field of study. Not so much anymore, a point I’ll elaborate on later.
OK, what should I learn then?
How to acquire and clean data. Take a source, put it into a database or cleaned CSVs. Seriously, that’s >80% of the work to building useable models.
Skills Needed
- Data scraping skills. Javascript and Python are great options.
- CSV skills. That’s the data lingua franca for most datasets (JSON is verbose, XML is old and enterprisey)
- Summarization skills. What variables do you have, can you develop a feel for how frequently the column is empty? What are the range of values? What’s the histogram look like, and percentiles?
- Statistical software. In python, that’s the pandas library
- SQL skills. Most data you acquire won’t be in SQL, but I like to store my data there. Maybe that’s just because I’m more comfortable doing SQL queries than pandas summarization, or maybe it’s because relational databases are great at storing data safely.
- Hack factor. You found the perfect data on someone’s website, but they have anti-scraping protections. How are you gonna get it?
- A desire to prove yourself wrong. The biggest danger with this stuff, why that diagram considers Statistics so important. So many people look for evidence they’re right in the data. That is just flat out wrong. The Scientific Method is your friend; do not psychologically incent yourself to be correct.
How to get these skills
Start hacking. Find some data you want, scrape it. Summarize it. Try to do a regression, then a prediction. Write about it.
Classes are de rigeur for many newbies, but I question whether they’ll have the toughness to produce valid results. Do your own analyses, try a few of the demo Kaggle competitions. Once you have a couple hundred hours of practical experience on several datasets, then dive into the theory.
Example
Check out my series on the SEC EDGAR database (1TB of U.S. regulatory financial data)
Conclusion
Get your hands dirty. This field isn’t a white glove, at a distance, theory based one. The way to learn is to do.
If you need any project ideas, I’ve got a million that I will never get around to building.
Other Concepts (possible future posts):
- Confusion Matrix
- Data Acquisition
- Transforming data (ETL)
- Setting up an analysis
- Coding the analysis
- Communicating the results
- Discipline
- Psychological Biases
- Artificial Intelligence